
目标
- 梳理yarn资源调优参数
- 调度器整理三种 区别是什么,CDH默认是什么
Yarn的资源调优
背景:假设单节点内存128G 16物理core
说明:
- 装完CentOS,消耗内存1G
- 系统预览15%-20%内存(包含1),以防全部使用导致系统夯住 和 oom机制事件,或者给未来部署组件预览点空间(
128*20%=25.6G==26G) - 假设只有DN NM节点,余下内存
128-26=102g- DN(自身)=2G,NN(自身)=4G,剩余
102-2-4=96G - container 内存的分配
yarn.nodemanager.resource.memory-mb96G container 总内存yarn.nodemanager.resource.memory-mb96G container 总内存yarn.scheduler.minimum-allocation-mb1G 极限情况下,只有96个container 内存1Gyarn.scheduler.maximum-allocation-mb96G 极限情况下,只有1个container 内存96G
container的内存会自动增加,默认1g递增,container范围:1-96个
- container 虚拟核的分配(vcore)
即 物理核:虚拟核 = 1:2 (16物理核==32虚拟核 )yarn.nodemanager.resource.pcores-vcores-multiplier2yarn.nodemanager.resource.cpu-vcores32个yarn.scheduler.minimum-allocation-vcores1个 极限情况下,只有32个containeryarn.scheduler.maximum-allocation-vcores32个 极限情况下,只有1个container
container范围:1-32
- DN(自身)=2G,NN(自身)=4G,剩余
- 官方建议
- cloudera公司推荐,一个container的vcore最好不要超过5,那么我们设置4
yarn.scheduler.maximum-allocation-vcores4 极限情况下,只有8个container
- 综合 memory + vcore
- 32个vcore,一个container分配4个vcore,可以分配8个container
- 分配虚拟核
yarn.nodemanager.resource.cpu-vcores32个yarn.scheduler.minimum-allocation-vcores1个yarn.scheduler.maximum-allocation-vcores4个 极限8个container
- 分配内存
yarn.nodemanager.resource.memory-mb96Gyarn.scheduler.minimum-allocation-mb1Gyarn.scheduler.maximum-allocation-mb12G 极限8个container
- 分配后每个container的虚拟核4个,内存12G。当然当spark计算时内存不够大,这个参数肯定要调大,那么这种理想化的设置个数必然要打破,以memory为主。
- 假如256G内存 56core,请问参数如何yarn参数如何调优
- 首先预估mr计算所用内存大小
- 系统占用 256*0.2=52G
- DN 占用 2G
- NM 占用 2G
- HBase 无
- 剩余内存容量 198G
- 如果物理核与虚拟核比例1:2,每个container 4vcore,56*2/4=28个container
- 最多分配28个container,每个container内存 198/28=>7G
- 每个container最大核数4,最大内存7G
- 首先预估mr计算所用内存大小
- 假如该节点还有其他组件,比如hbase regionserver 进程,那么如何设置?
如:hbase regionserver 30G
减去其他进程占用的内存后,再划分mr计算内存。
内存&&核数默认参数配置(yarn-default.xml)
内存参数默认值
KEY VALUE DESC yarn.nodemanager.resource.memory-mb -1 可以分配给容器的内存总量(以MB为单位) yarn.scheduler.minimum-allocation-mb 1024 RM上每个容器分配的最小内存 yarn.scheduler.maximum-allocation-mb 8192 RM上每个容器分配的最大内存
核数参数默认值
KEY VALUE DESC yarn.nodemanager.resource.pcores-vcores-multiplier 2 物理核:虚拟核比例 yarn.nodemanager.resource.cpu-vcores -1 可以为容器分配的vcore总数量 yarn.scheduler.minimum-allocation-vcores 1 RM上每个容器分配的最小虚拟核数 yarn.scheduler.maximum-allocation-vcores 4 RM上每个容器分配的最大虚拟核数
Yarn的三种调度器
- Apache hadoop2.x 默认调度器是 Capacity Scheduler (计算调度器)
- CDH 默认的调度器是 Fair Scheduler (公平调度器)
- FIFO Scheduler(先进先出调度器)
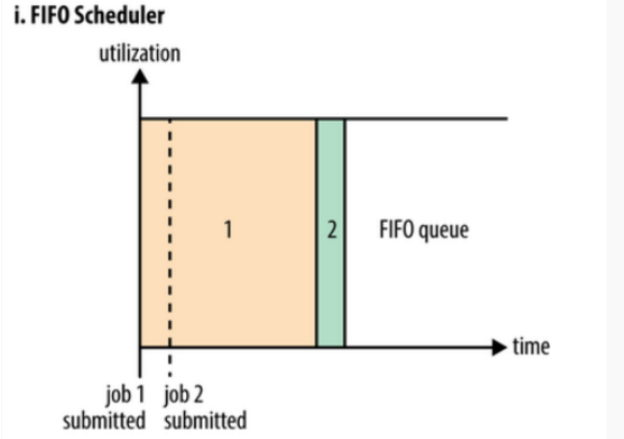
FIFO Scheduler把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。
FIFO Scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。在共享集群中,更适合采用Capacity Scheduler或Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资源。从图中可以看出,在FIFO 调度器中,小任务会被大任务阻塞。 - Capacity Scheduler (计算调度器)
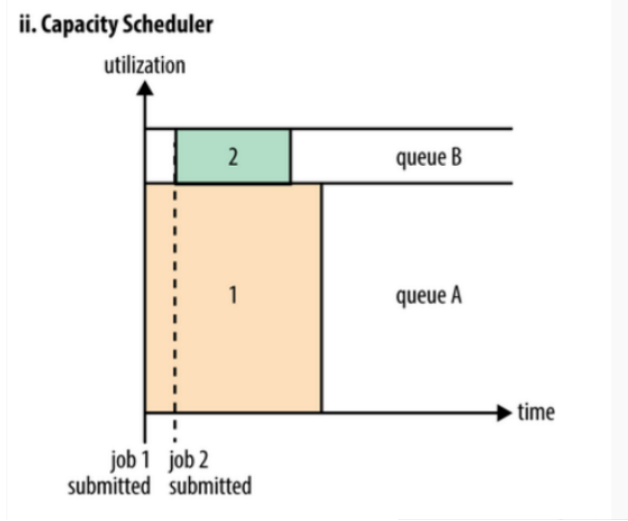
Capacity Scheduler 有一个专门的队列来运行小任务,但是为了小任务专门设置一个队列预先占用一定的集群资源。这会导致大任务的执行时间落后FIFO的调度时间。 - Fair Scheduler (公平调度器)
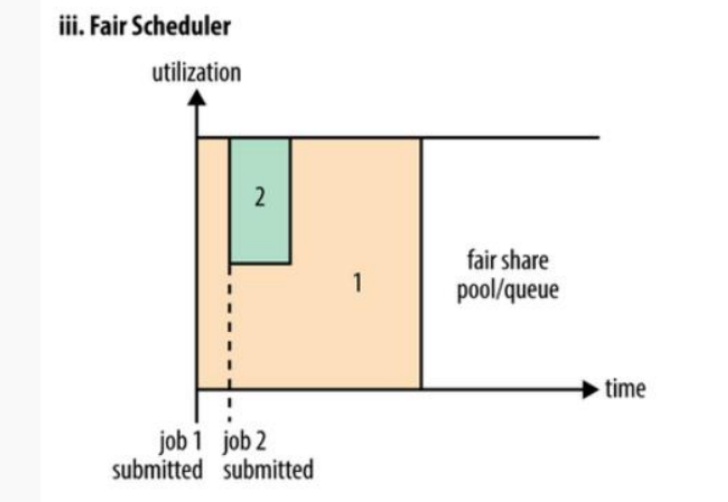
Fair Scheduler不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。如上图所示,当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小job提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
需要注意的是,在上图Fair调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终的效果就是Fair调度器即得到了高的资源利用率又能保证小任务及时完成。常用命令
yarn application -kill <Application ID> # 杀死正在运行的Job