
目标
- 整理HDFS读写流程
- 整理pid文件
- 整理HDFS常用命令
- 整理HDFS的回收站机制
- 整理多节点和单节点的数据均衡
- 整理安全模式(safe mode)
读写流程
读流程(FSDataInputStream)
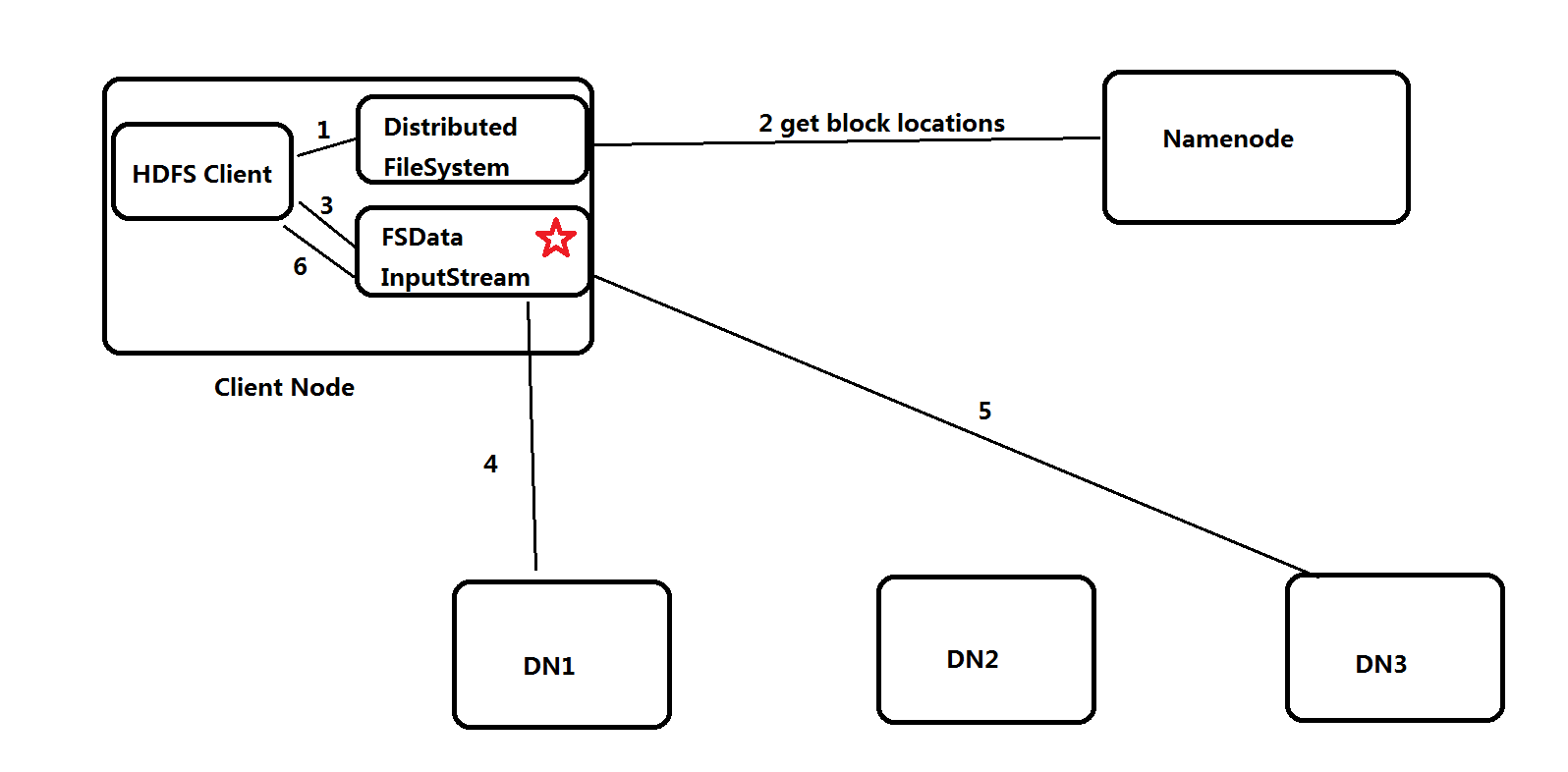
- Client调用FileSystem.get()方法,获取分布式文件系统实例DistributedFileSystem
- 调用FileSystem.open()方法,与NN进行rpc通信,返回该文件的部分或者全部的block列表,也就是返回FSDataInputStream对象
- Client调用FSDataInputStream对象的read()方法,与第一个块最近的DN连接并读取数据
- 如果第一个块的数据读取完,就关闭与当前DN的通信,然后去该块的第二个DN地址读取数据,依次类推。这些操作对客户端来说是透明的、无感知的,从客户端的角度看来只是在读一个持续不断的数据流。
- 如果第一批块都读取完,DFSInputStream会去NN拿下一批块的位置信息,然后继续读取,如果所有的块都读完了,这时就会关闭输入流。
注: 如果在读取数据时,DFSInputStream和DN的通信发生异常,就会去该块的第二个DN地址读取,并且会记录失败块和DN信息,下次不会再读取。同时读取时,DFSInputStream也会检查块的校验和,如果发现一个块损坏,就会先报告到NN,然后DFSIputStream就会去该块的第二个DN地址读取。
写流程(FSDataOutputStream)
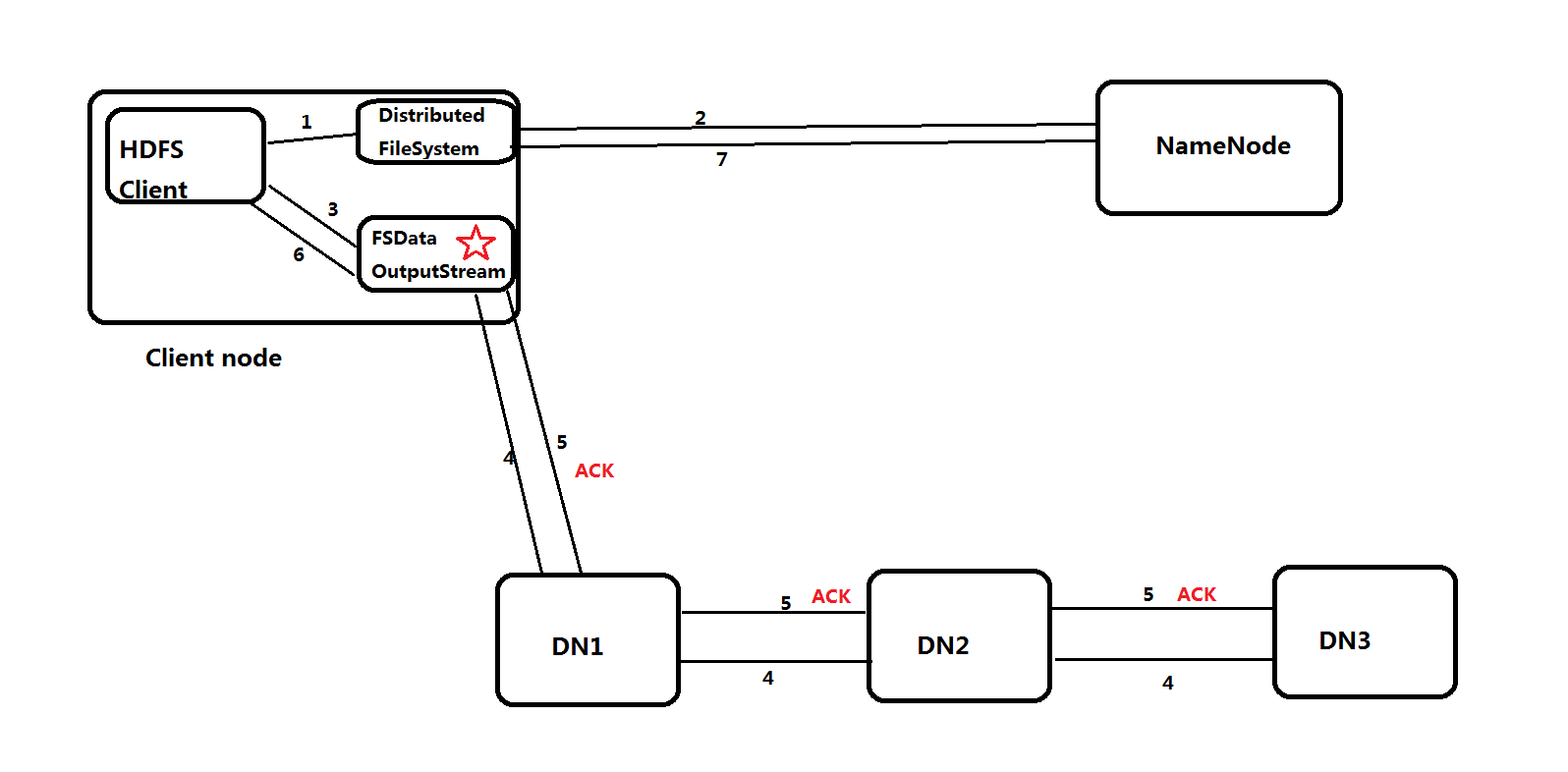
- Client调用FileSystem.get()方法,获取分布式文件系统实例DistributedFileSystem
- 调用FileSystem.create()方法,与NN进行rpc通信,并创建文件,在创建文件前NN会进行校验,比如校验文件是否存在或是否有权限创建文件等。如果校验通过,就创建一个新文件,不关联任何的block块,并返回一个FSDataOutputStream对象;如果校验不通过,就返回错误信息。
- Client调用FSDataInputStream对象的write()方法,先将第一块的第一个副本写到第一个DN,第一个副本写完,就传输到第二个DN,依次类推。如果所有的副本都写完 ,第三个DN就会返回一个ack包给第二个DN,第二个DN接收到ack包且自身ok,就会返回一个ack包给第一个DN,依次类推。如果FSDataOutputStream对象接收到ack包,标志第一个块的3个副本写入完成。
- 余下的块依次这样写,当所有块写完后,Client调用FileSystem.close()方法,关闭输出流。
- 再调用FileSystem.complete()方法,通知NN文件写入完成。
pid文件
存储位置
hdfs/yarn 进程启动后,pid文件生成后是存储在哪里呢?
我们查看hadoop-env.sh文件,发现hadoop生成的默认pid文件是存储到/tmp目录的
# The directory where pid files are stored. /tmp by default. |
查看/tmp目录
pid文件详解
查看start-dfs.sh
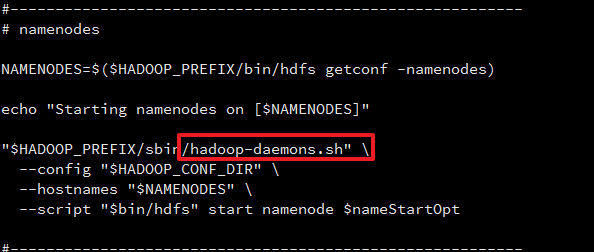
查看hadoop-daemon.sh
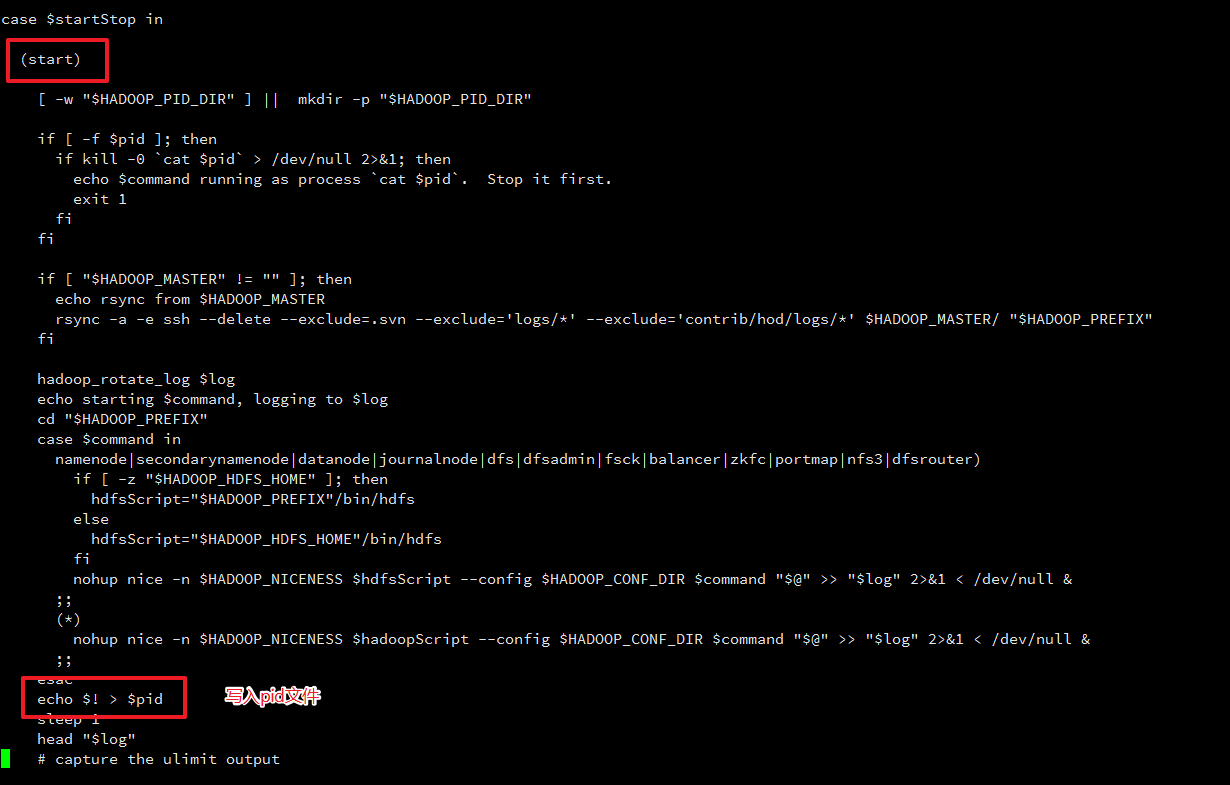
这里我们得出如下结论:
- hadoop启动的时候,会生成pid文件,并把 ? 写入pid文件
- hadoop停止的时候,会去pid文件中获取 ?,然后停止进程,最后删除pid文件
同时我们大胆猜测一下pid文件内容是:进程号
这里我们做出如下验证:
查看NN进程号和pid文件内容
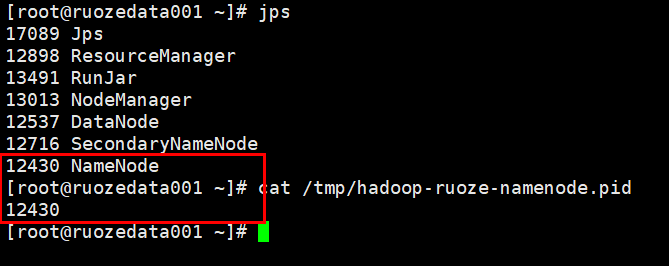
如果我们修改NN的pid文件名,那么NN进程停止时,会找不到原有pid文件,也就不会停止NN进程了
/tmp目录弊端
因为Linux的机制,/tmp 目录文件默认存储周期为1个月,超过1个月会自动清空不在规则以内的文件(没有访问的文件),如果Hadoop启动超过30天,pid文件会被自动清理。
修改pid文件目录
创建/home/ruoze/tmp目录
mkdir /home/ruoze/tmp
修改文件夹权限
chmod -R 777 /hadoop/ruoze/tmp
修改hadoop-env.sh文件和yarn-env.sh文件
# hadoop-env.sh
export HADOOP_PID_DIR=/home/ruoze/tmp
# yarn-env.sh
export YARN_PID_DIR=/home/ruoze/tmp
HDFS常用命令
- 待更新
HDFS回收站机制
- 待更新
多节点和单节点的数据均衡
- 待更新
安全模式(safe mode)
- 待更新