
目标
- 为什么要改变HDFS /tmp 存储目录
- 整理块大小、副本数的理解
- 整理小文件的理解
- 整理HDFS架构
- 整理SNN流程
为什么要改变HDFS /tmp 存储目录
HDFS NN/DN/SNN tmp文件存储目录默认是由core-default.xml中hadoop.tmp.dir参数决定的,如下:
| KEY | VALUE | DESC |
|---|---|---|
| hadoop.tmp.dir | /tmp/hadoop-${user.name} | A base for other temporary directories. |
注:因为Linux的机制,/tmp 目录文件默认存储周期为1个月,超过1个月会自动清空不在规则以内的文件,为了防止文件丢失,我们需要改变hadoop的tmp文件存储目录
- 修改
core-site.xml的hadoop.tmp.dir参数vi core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property> - 修正权限
chmod -R 777 /home/ruoze/tmp
mv /tmp/hadoop-ruoze/dfs /home/ruoze/tmp/ - 重新启动hdfs
stop-dfs.sh
start-dfs.sh
整理块大小、副本数的理解
块大小
hadoop 1.x 的块大小是64M,hadoop 2.x的块大小是128M,块大小是由hdfs-default.xml文件中dfs.blocksize参数控制。block是hdfs最小读写单元,它可以根据实际需求改变块大小,但一般不建议修改。
| KEY | VALUE | DESC |
|---|---|---|
| dfs.blocksize | 134217728(128M) | The default block size for new files, in bytes. You can use the following suffix (case insensitive): k(kilo), m(mega), g(giga), t(tera), p(peta), e(exa) to specify the size (such as 128k, 512m, 1g, etc.), Or provide complete size in bytes (such as 134217728 for 128 MB). |
- 块大小为什么要设计成128M?
因为目前磁盘的传输速率普遍是在100M/s左右,为了最小化寻址时间,所以设计成128M。
副本数
hdfs的副本的设计让hadoop具有高可用的特性,数据在不同节点存储多份,使数据不会轻易丢失。副本是存储在DN中的,由hdfs-default.xml文件中dfs.replicatione参数控制,副本数必须小于等于DN节点数,在伪分布式部署中,副本数为1;在集群部署中,副本数为3,可以根据实际需求修改,但一般不建议修改。
| KEY | VALUE | DESC |
|---|---|---|
| dfs.replication | 3 | Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time. |
整理小文件的理解
在生产中,一般情况下,小文件是指文件大小小于10M的文件,由于NN主要用来存储文件的元数据信息(在内存中),如果小文件数过多,那么对应小文件的block数也过多,那么NN需要维护的块的元数据信息也过多,又因为NN的内存大小有限,所以过多的小文件会对NN造成很大负载。
为了应对小文件过多的情况,一般情况下,我们选择把小文件合并成大文件在上传至hdfs上或者上传到hdfs后再合并,具体解决方案后面补充。
整理HDFS的架构
HDFS由Client、NameNode、DataNode、SecondaryNameNode这四部分组成。
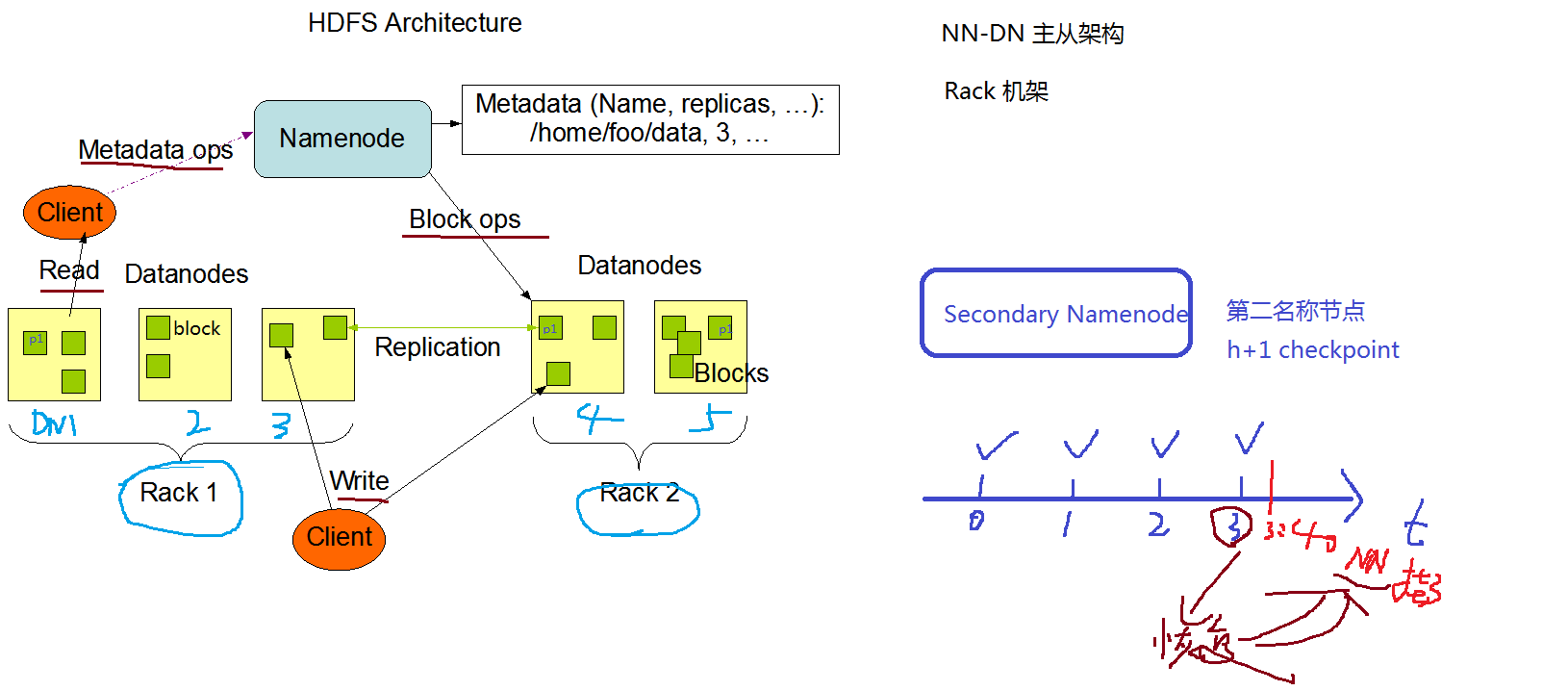
NameNode
NameNode 简写为NN,也被称为名称节点,它是HDFS主从架构中的老大,它主要用来存储文件系统的命名空间,且维护着整个文件系统的目录树以及目录树中所有子目录的文件的元数据信息。这些信息是以两个文件形式保存在本地磁盘上的,镜像文件fsimage和编辑日志文件editlog。文件系统的命名空间,如下:
- 文件的名称
- 文件的目录结构
- 文件的属性、权限、创建时间、副本数
- 文件对应被切分为哪些数据块(包含副本数),以及数据块分布在哪些DN节点上。
说明:NN节点不会持久化存储这种映射关系,而是在集群启动和运行时,DN节点会定期向NN发送blockreport(默认间隔6小时,由dfs.blockreport.intervalMsec参数控制),NN节点接收到消息后,会在内存中动态维护这种映射关系。
DataNode
DataNode 简写为DN,也被称为数据节点,它是HDFS主从架构中的小弟,它主要用来存储数据块和数据块校验和,这些信息是以Linux文件的形式保存在本地磁盘上的。DataNode会定期向NameNode发送心跳(默认3s)和块报告(默认6小时)。
心跳
DN发送心跳是为了告诉NN我还活着,心跳间隔由hdfs-default.xml文件中的dfs.heartbeat.interval参数控制,默认每3s发送一次。KEY VALUE DESC dfs.heartbeat.interval 3 Determines datanode heartbeat interval in seconds. 块报告
DN发送块报告是为了扫描数据目录并协调内存和磁盘块之间的差异,块报告间隔由hdfs-default.xml文件中的dfs.datanode.directoryscan.interval参数和dfs.blockreport.intervalMsec参数控制的,默认每6小时发送一次。
在生产环境中,建议缩短周期为3小时。KEY VALUE DESC dfs.datanode.directoryscan.interval 21600 Interval in seconds for Datanode to scan data directories and reconcile the difference between blocks in memory and on the disk. dfs.blockreport.intervalMsec 21600000 Determines block reporting interval in milliseconds.
SecondeayNameNode
SecondeayNameNode 简写为SNN,也被称为第二名称节点,它是HDFS主从架构中的老二,它会定期合并fsimage+editlog文件,这个过程也被称为checkpoint。文件合并间隔是由hdfs-default.xml文件中的dfs.namenode.checkpoint.period参数(默认1小时)和dfs.namenode.checkpoint.txns参数(默认1000000条)控制的,两个参数满足其一即可触发合并机制。
| KEY | VALUE | DESC |
|---|---|---|
| dfs.namenode.checkpoint.period | 3600 | The number of seconds between two periodic checkpoints. |
| dfs.namenode.checkpoint.txns | 1000000 | The Secondary NameNode or CheckpointNode will create a checkpoint of the namespace every ‘dfs.namenode.checkpoint.txns’ transactions, regardless of whether ‘dfs.namenode.checkpoint.period’ has expired. |
注:虽然SNN能够减轻单点故障,但是还会有风险,因为在checkpoint完的下一个时间周期内发生故障,数据是恢复不了的
SecondaryNameNode和NameNode的交互流程
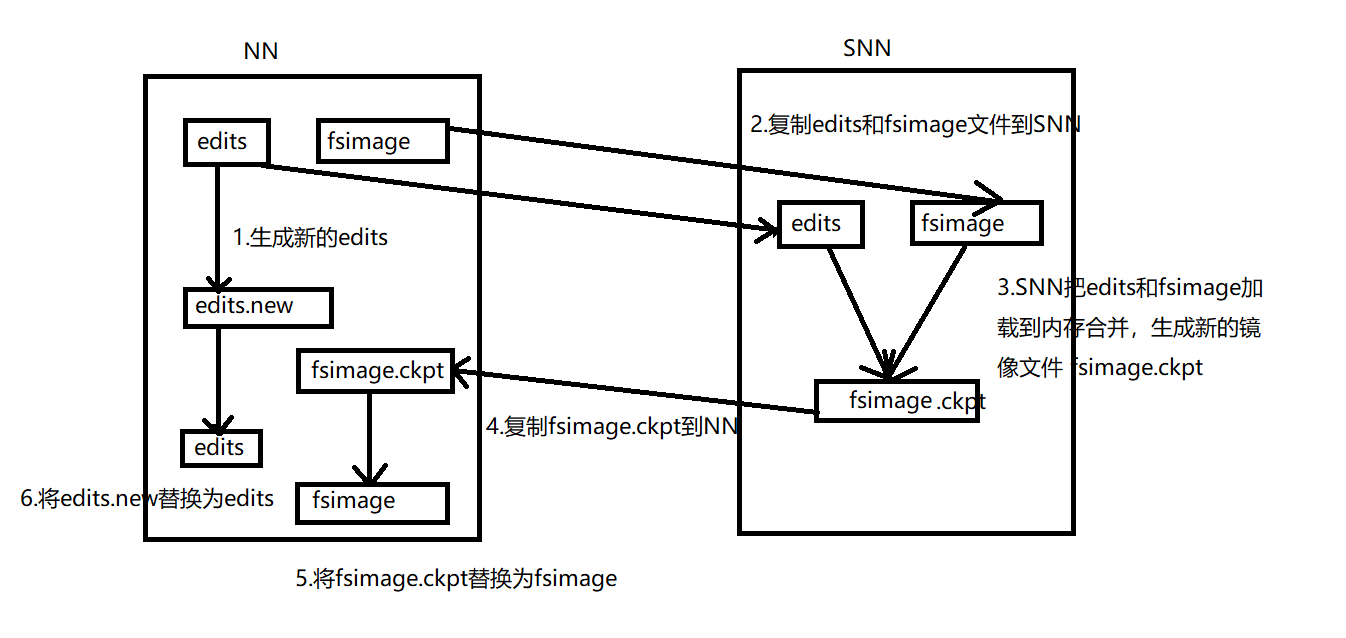
- NN滚动正在写入的editlog文件,并生成新的空的edits.new文件,并将以后的更新操作写入edits.new文件。
- 拷贝原来的editlog和fsimage文件到SNN
- SNN把edits和fsimage文件加载到内存合并,生成新的镜像文件fsimage.ckpt
- 新生成的fsimage.ckpt文件会被拷贝到NN节点
- fsimage.ckpt文件重命名为fsimage,并替换掉原来的fsimage.ckpt文件
- edits.new文件重命名为edits,并替换掉原来的edits.new文件
NameNode&DataNode的内存分配
建议DN进程分配2G,NM进程分配4G
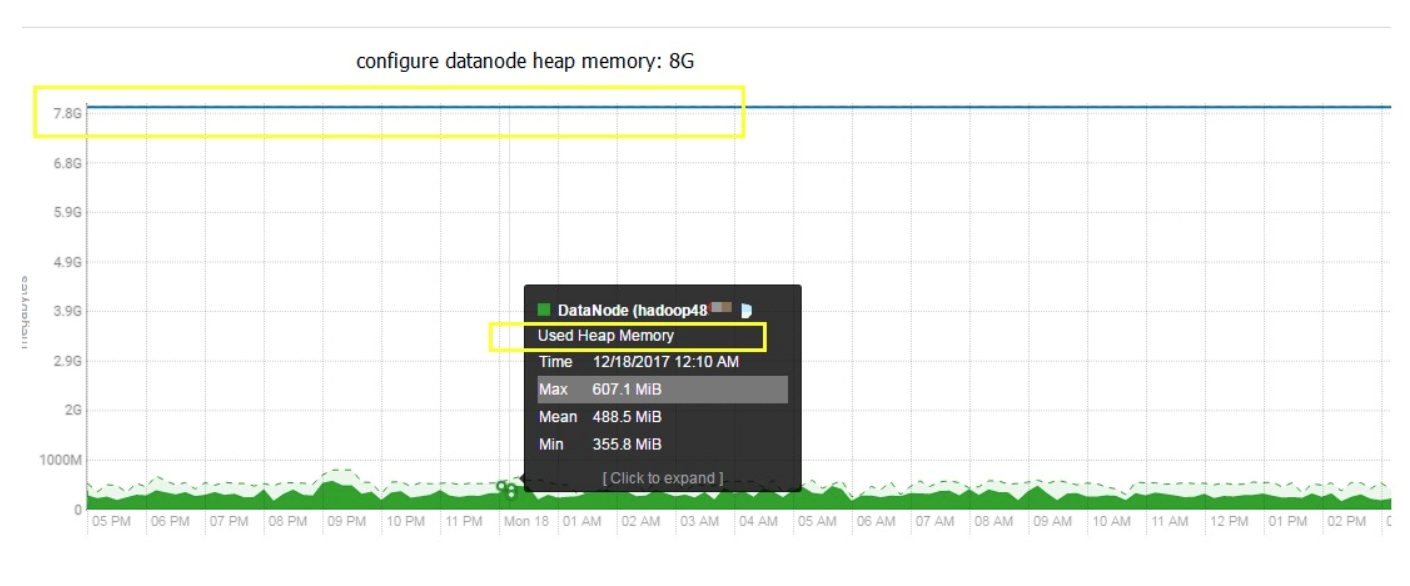
DN
我们生产上DN是设置8G,但是查看NN监控发现,使用率只要607M,经过长时间验证,只需配置2G即可
NN
NN的内存多少,和文件的个数有关系,因为一般来说一个文件一个块,在NN存储维护是150字节-250字节,所以设置NN为4G已经可以维护很多很多文件的元数据信息了,如果未来生产上真的数据文件特别多,那么找到维护时间,调大NN内存即可